如何搭建高并发系统
目录
高并发系统设计
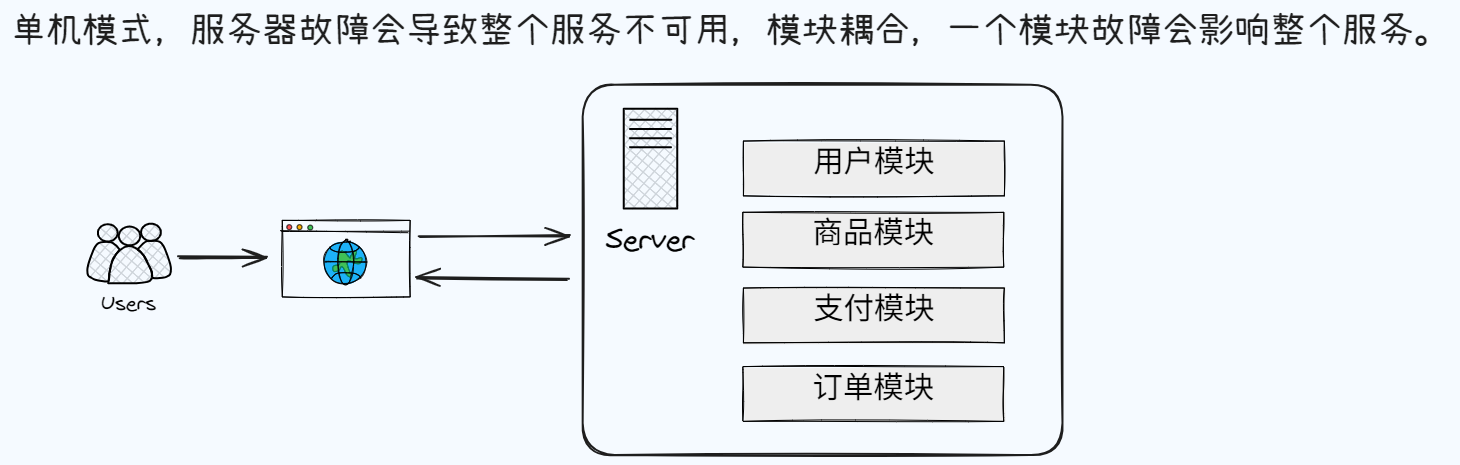
在短时间内有大量用户访问,且能快速,稳定响应的系统。
核心特性:
- 高性能
- 高可用

设计方向:

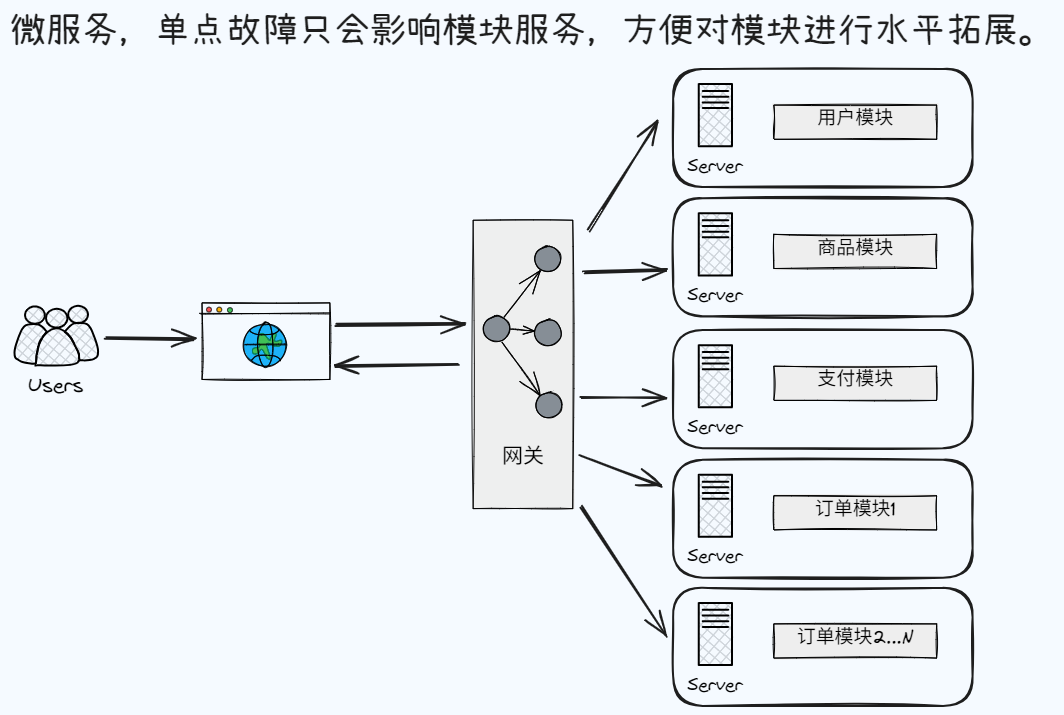
- 系统拆分:考虑微服务增加可用性,降低耦合性,提高扩展性。
- 缓存加速:使用redis能缓存数据库,加速查询。
- MQ使用:使用消息队列对流程进行解耦,提高系统可扩展性。以及对任务进行削峰填谷。
- 数据分离:使用垂直分库和水平分库等技术提高数据库系统的查询性能。
- 读写分离:解决实际使用过程中“读多写少”的使用场景。
- 服务监控:监控系统运行情况,快速定位问题。
上面几个点是最常用的,当然也有其它点,比如:限流熔断,降级处理等等技术。
系统拆分
缓存加速
1 浏览器缓存
浏览器缓存是指将网页中的资源(如HTML、CSS、JavaScript、图像等)存储在用户的浏览器内部,以便在后续请求同一资源时可以直接从本地缓存中获取,而无需再次从服务器下载。
适用场景
- 静态内容变化较少的网页和静态资源。
- 显著提升网站性能和用户体验,减少服务器负载。
常见用法
使用响应头中的 Expires 和 Cache-Control 字段控制缓存行为:
- Expires字段:指定缓存的过期时间(具体日期和时间)。
示例:Expires: Mon, 31 Dec 2022 23:59:59 GMT。 - Cache-Control字段:提供更灵活的缓存控制选项。
max-age=3600:资源可在1小时内直接从缓存中获取。no-cache:缓存但不使用缓存。no-store:禁止缓存。
注意事项
- 适用于实时性不敏感的数据(如商品框架、商家评分、广告词)。
- 实时性要求高的数据不适合使用浏览器缓存。
2 客户端缓存
将数据存储在浏览器中,以提高访问速度和减少服务器请求。
适用场景
- 大促期间,提前下发素材(如JS/CSS/图片)到客户端缓存,避免高流量压力。
- 兜底数据或样式文件缓存,确保服务端异常时App正常运行。
3 CDN缓存
CDN(Content Delivery Network)是分布式网络,由边缘节点服务器组成,用于缓存静态页面数据、活动页面、图片等。
适用场景
- 网站访问量大、访问速度慢、数据变化不频繁的场景。
常用工具
- Cloudflare、Akamai、Fastly、AWS CloudFront。
4 反向代理缓存
在反向代理服务器上缓存请求的响应,提高性能和用户体验。
适用场景
- 访问外部服务速度慢,但数据变化不频繁的场景。
常用工具
- Nginx:通过
Http模块与proxy_cache模块配置缓存策略。 - Varnish:专用于反向代理缓存的开源软件。
- Squid:功能强大的缓存代理服务器。
5 本地缓存
将数据存储在客户端的存储介质中(硬盘、内存、数据库)。
适用场景
- 频繁访问数据、离线访问、减少带宽消耗。
分类
- 磁盘缓存:存储在硬盘上,加速数据读取。
- CPU缓存:处理器内部高速存储器,提高性能。
- 应用缓存:内存中的应用程序数据(如Java的堆内/堆外缓存)。
6 分布式缓存
将缓存数据分散存储在多台服务器上。
适用场景
- 高并发读取、数据共享、弹性扩展、降低后端请求次数。
常用工具
- Redis:高性能键值存储,支持数据分片和负载均衡。
- Memcached:分布式内存对象缓存系统。
- Hazelcast:分布式内存数据网格平台。
MQ解耦/异步/削峰
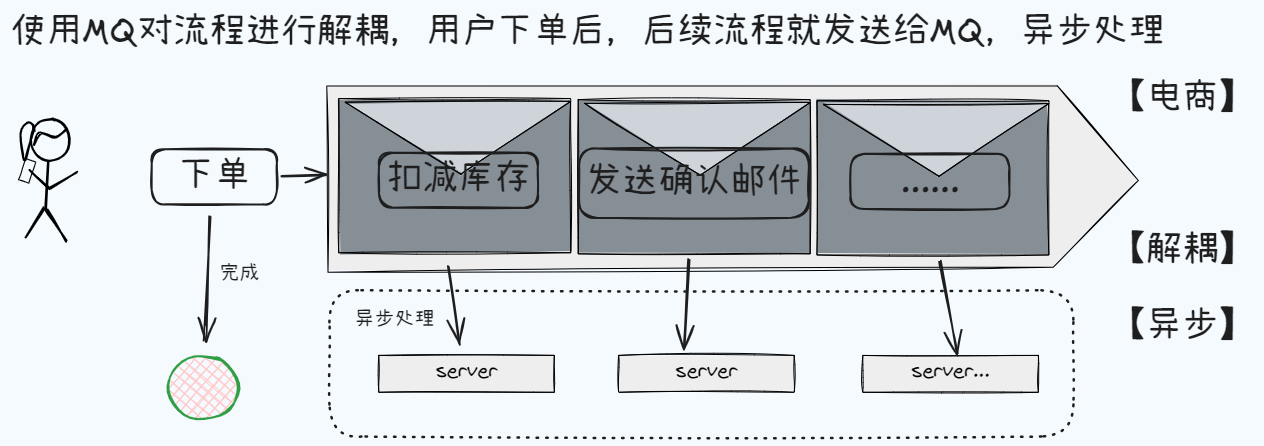
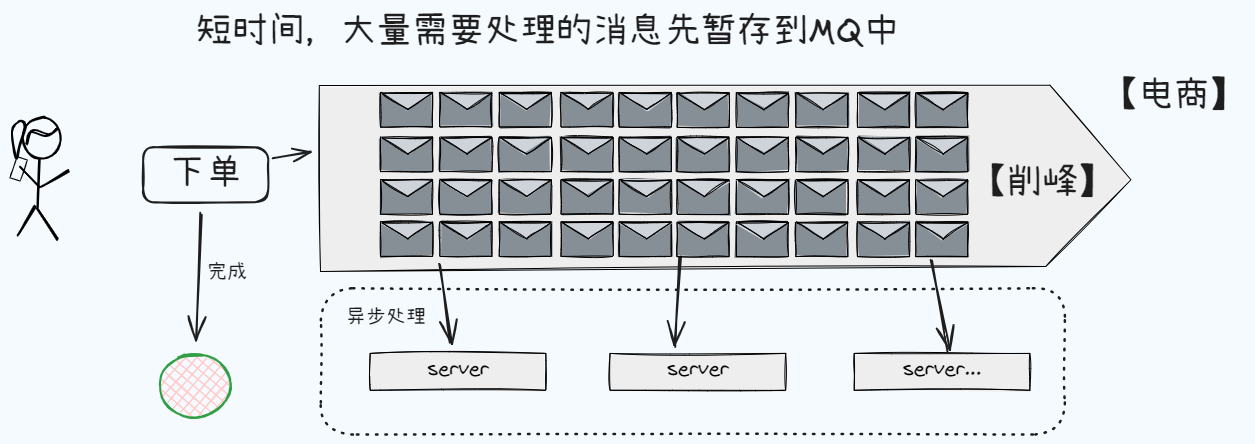
假设电商系统有这样一个流程:用户下单以后,需要去数据库扣减库存,然后给用户发送确认邮件,最后更新用户的积分:

如果用户下单量很大,那么每次下单都需要去数据库扣减库存,给用户发送确认邮件,最后更新用户的积分,这样就会导致数据库压力很大,用户下单速度变慢。而且一旦一个流程失败,就会导致这个流程失败。所以可以通过MQ来解耦,异步,削峰。
数据分离
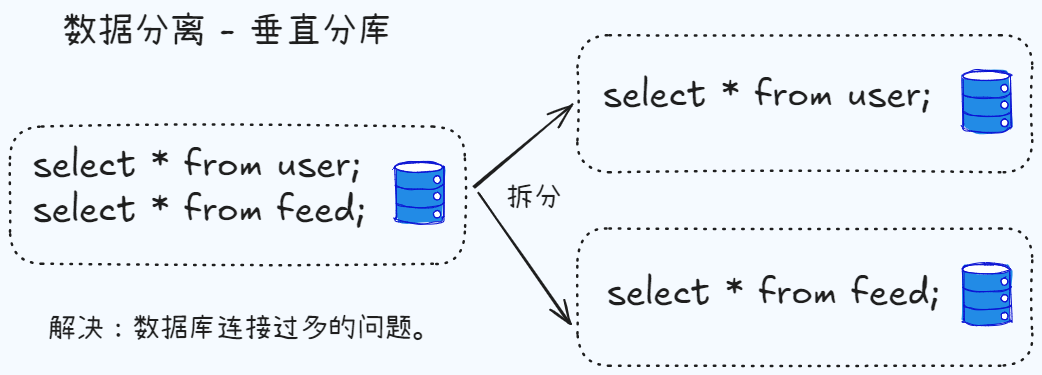
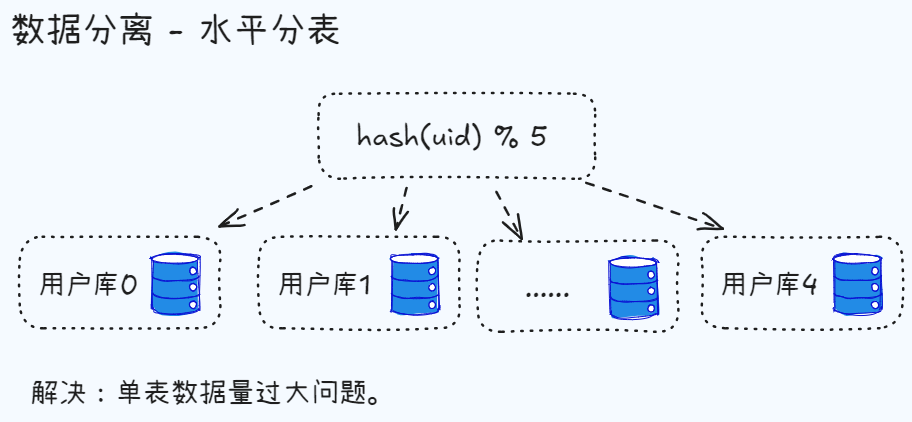
如果所有服务都请求一个数据库,一旦用户量大了,数据库压力就会很大,出现各种问题。比如,数据库连接数资源很快就会耗尽。这个时候就需要对数据进行分离,常见的两种方式是垂直分库和水平分库:
- 垂直分库:将不同的业务数据分离到不同的数据库中,比如商品库,用户库,订单库等。
- 水平分库:将同一个业务数据分离到不同的数据库中,比如将用户数据分离到不同的数据库中,每个数据库中的用户数据是相同的,但是数据库的名称不同。(针对大表特别有用)
读写分离
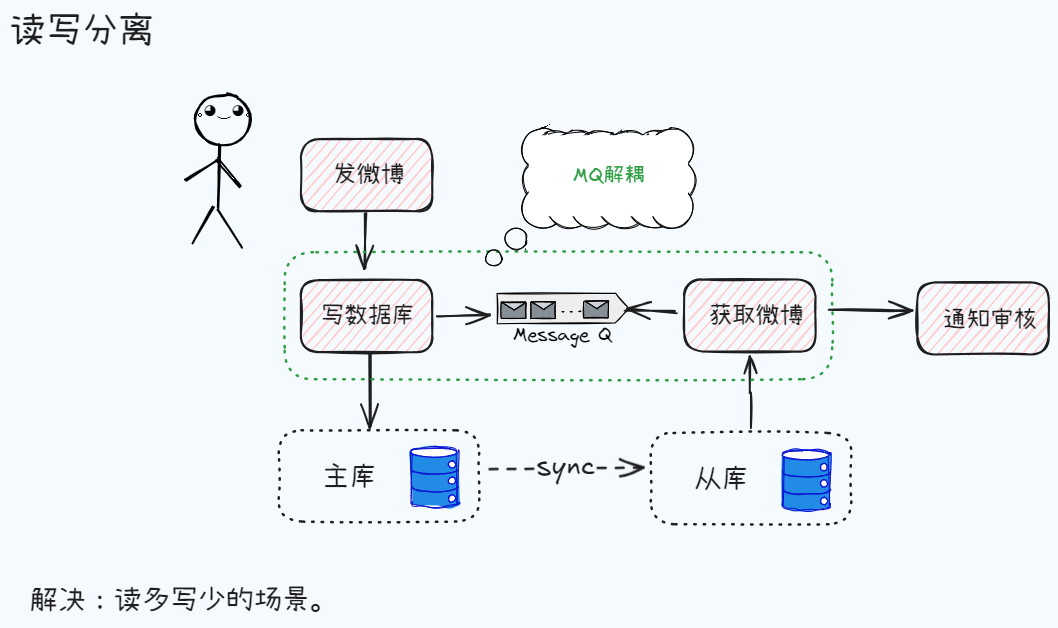
读写分离可以很好提高数据库的读取性能,主要基于以下几个核心原因:
1. 分担主库压力
- 主库通常负责处理写操作(如插入、更新、删除),而从库专门用于处理读操作(如查询)。
- 在“读多写少”的业务场景中(如电商、社交平台),读请求的数量远高于写请求。通过读写分离,可以将大量读请求分散到多个从库上,避免主库因高并发读请求而成为性能瓶颈。
2. 并行处理能力
- 主库和从库可以并行工作。主库专注于写操作,从库专注于读操作,互不干扰。
- 从库可以部署多个实例,通过负载均衡技术(如轮询、一致性哈希)将读请求分配到不同的从库上,进一步扩展读性能。
3. 利用从库的冗余性
- 从库是主库的数据副本,通常通过主从复制(如MySQL的binlog)实现数据同步。
- 多个从库可以同时服务读请求,而主库只需处理写请求和少量的关键读请求(如需要强一致性的场景)。
4. 优化硬件资源
- 主库和从库可以差异化配置硬件。例如:
- 主库:配置更高的CPU和磁盘I/O性能,以应对写操作的密集计算和持久化需求。
- 从库:配置更大的内存和SSD存储,以加速查询响应速度。
5. 减少锁竞争
- 写操作通常会加锁(如行锁、表锁),如果读请求直接访问主库,可能会与写操作产生锁竞争,导致查询延迟。
- 读写分离后,读请求访问从库(通常配置为“读已提交”或“快照隔离”级别),避免了与主库写操作的锁冲突。
6. 地理分布优化
- 从库可以部署在离用户更近的地理位置(如不同区域的机房),减少网络延迟,提升读请求的响应速度。
适用场景
- 高并发读:如商品详情页、新闻列表、社交动态等。
- 实时性要求较低:从库的数据同步通常有毫秒级延迟,适合对数据实时性要求不高的场景。
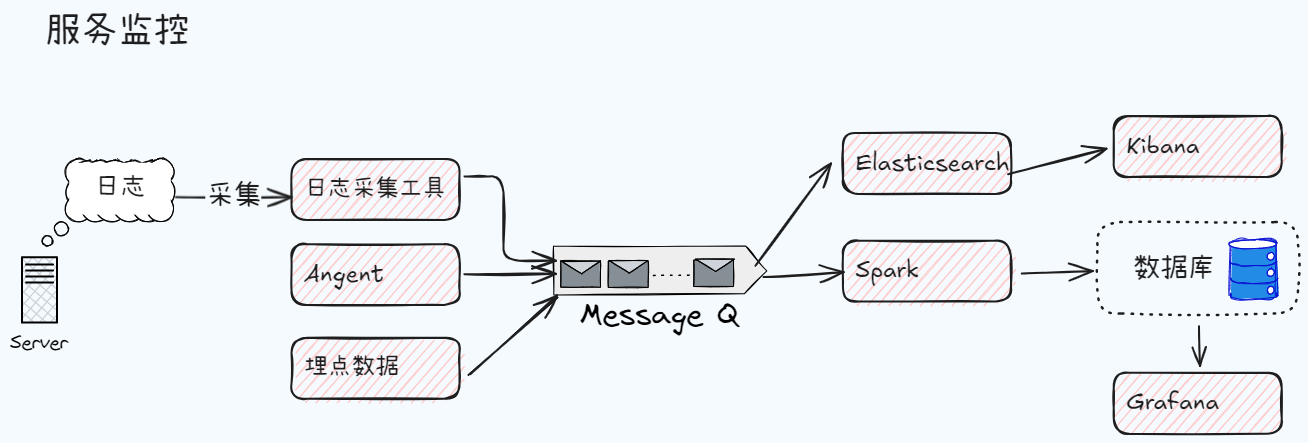
服务监控